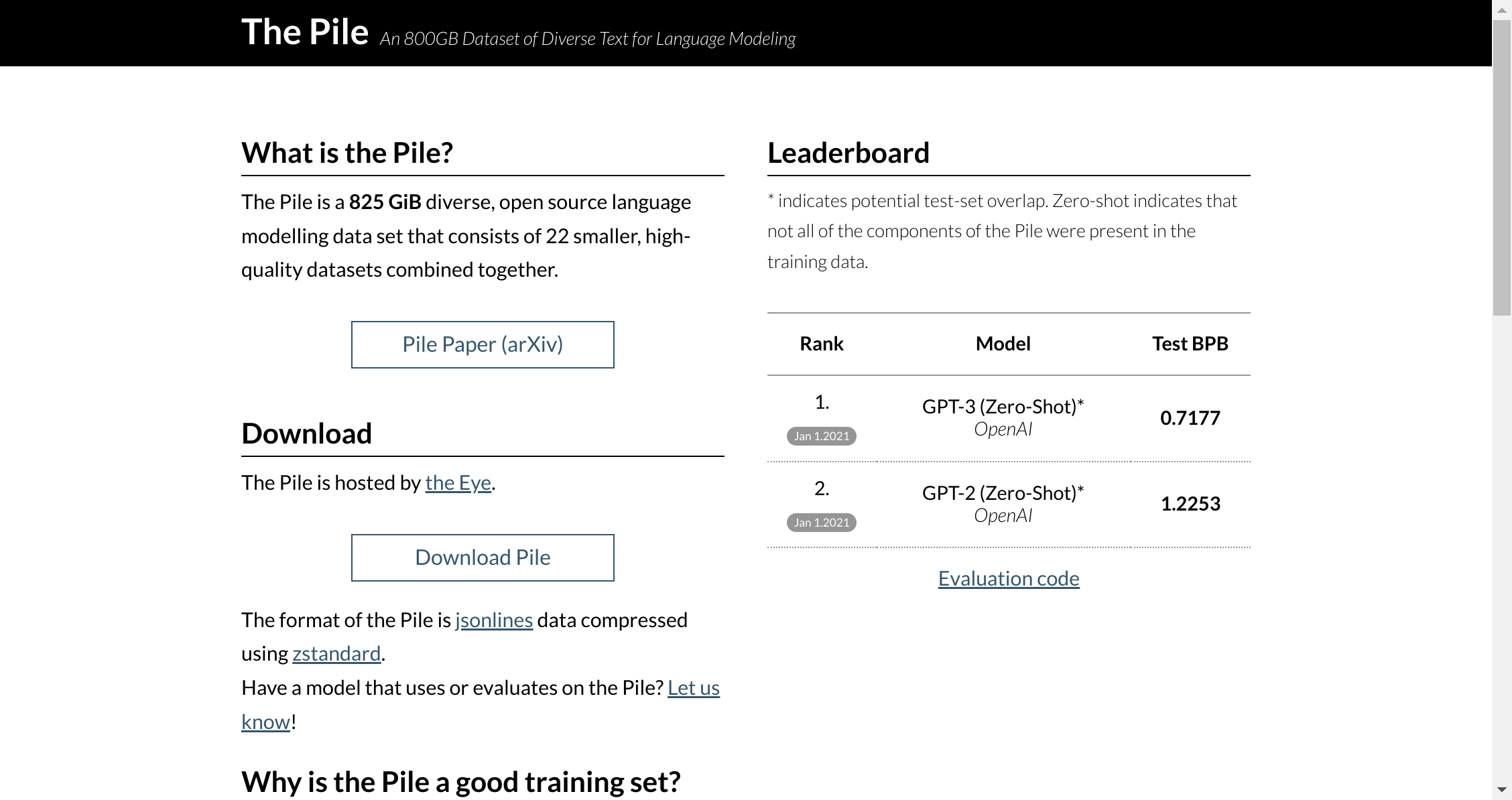
The Pile is an 825 GiB, open source language modelling data set developed by EleutherAI. This dataset comprises of many smaller datasets merged together to create a diverse dataset that can help improve the generalization abilities of models trained using The Pile.
Recent research has indicated that large models benefit significantly from diversity in their training data sources, as this leads to improved cross-domain knowledge and downstream generalization capability. Experiments conducted have shown that models trained on The Pile perform better than those trained with traditional language modelling benchmarks, as well as showing significant improvements on Pile BPB tests.